本文要点
- 加权 token 综合单价从 5 月底近 $2 百万 tokens 回落到 6 月 $1.6 至 $1.7 百万 tokens
- 企业 workflow 从 frontier 单价线性外推转为 planning 与 execution 分层路由
- DeepSeek V4-Flash、Claude Haiku、gpt-5.4-nano 形成低于 $1 百万 tokens 的低价档共识
阅读辅助
先看数字、证据和来源,再读正文。
LLM Token 综合单价 6 月出现首个明显回落,frontier 单价线性外推的叙事被打破
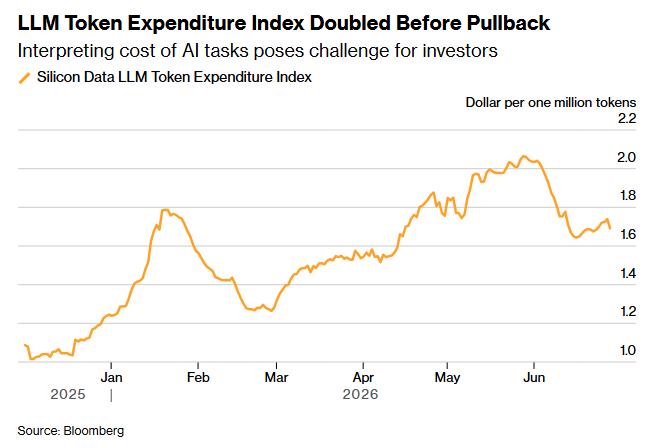
2025-12-31 · 2025 年底:LLM Token Expenditure Index 起点约 $1 百万 tokens 附近
6 月 LLM 行业最值得追问的一条数据,不是 frontier 单价本身——那是各家厂商自己挂出来的公开数字——而是 @AlphaguyTrading 公开的那个 LLM Token Expenditure Index:从 5 月底接近 $2/百万 tokens 跌到 6 月 $1.6–1.7/百万 tokens,单月 ~15% 的回落,是该指数自 2025 年底建立以来的首个明显拐点。
但这条数据之所以值得追问,不是因为它「指向一个拐点」,而是因为 这个指数的加权口径、加权样本、缓存命中假设全部没有公开——指数由单一财经 KOL 账号自跟踪自发布,目前没有任何第三方追踪平台(Artificial Analysis、OpenRouter、Helicone 等)给出过交叉印证。换句话说,指数告诉市场「拐点出现了」,但同时它也告诉市场「拐点是不是真出现」这件事,目前没有可独立验证的数据——这是 7–9 月真正需要回答的问题,也是这篇报道把指数读数放上头条但不打算把它当作定论的根本原因。
一、读数本身:一条未被交叉验证的曲线
指数曲线原始截图(由 @AlphaguyTrading 7 月 4 日推文附图)呈现如下轨迹:
- 2025 年 12 月:指数起点约 $1/百万 tokens
- 2026 年 5 月底:指数冲高到接近 $2/百万 tokens(自 2025 年底近乎翻倍)
- 2026 年 6 月:指数单月明显回落,稳定在 $1.6–1.7/百万 tokens 区间,跌幅约 15%
- 2026 年 7 月 4 日:@AlphaguyTrading 公开指数与拐点判断,首次被市场广泛传播
读数本身具备两点不可忽视的事实属性:第一,它来自单一来源——@AlphaguyTrading 长期跟踪但未公开方法论,也没有任何第三方独立平台(Artificial Analysis、OpenRouter、Helicone、OpenPipe 等)给出过同类指数的对照读数;第二,官方一手厂商定价页(Anthropic、OpenAI、DeepSeek)过去半年没有任何 frontier 单价本身的下调动作——也就是说,指数下跌 15% 不能被任何官方价格表直接解释。
这意味着指数下跌的成因至少有三种可能:token mix 迁移(低价档 token 占比上升导致加权均价下降)、6 月特殊节奏(年中预算执行 + 海外暑期 + 缓存命中率波动)、或口径偏差(指数本身的设计就有结构性放大效应)。这三种解释各有合理性,而指数本身无法区分——这是所有后续分析的前提。脱离这个前提谈「拐点是真的」,等于把单一 KOL 的方法论假设当作事实接受。
二、口径疑点:为什么「6 月」可能是暑假一次性扰动
把焦点放到最容易被忽视但最重要的一点:加权口径未公开。这一节列出至少三个疑点,使 6 月这个拐点不能被简单当成趋势的开端。
疑点一:加权样本是否覆盖了 frontier token? 如果指数的「加权 token 量」主要采样自公开 API 路由服务商(OpenRouter、OpenPipe、Portkey 等)而非 Anthropic / OpenAI 直接计费 API,那么指数对 Anthropic ARR 的代表性需要打折扣——OpenRouter 等路由上的 token mix 已经偏向了低价档。@AlphaguyTrading 的指数走的是哪条取样路径,推文里没有写;如果取样路径偏向 routing 服务商,那 6 月单月 15% 跌幅本身就可能只是「路由占比上升」的一个副产品,而非 frontier token 收入被挤压的证据。
疑点二:cache hit 折扣是否计入指数分母? DeepSeek-V4-Flash 的 cache hit 输入仅 $0.0028/百万 tokens,与 cache miss 输入 $0.14 相差 50 倍;Anthropic 的 cache hit 是 base 的 0.1×(Opus 4.8 cache hit 约 $0.50/百万 tokens)。如果指数按「实际计费价」加权,那 prompt cache 命中率任何 10 个百分点的波动就会让加权均价出现约 5% 的跳动——6 月单月 15% 跌幅完全在 cache 命中率结构性变化的可解释范围内,不需要假设 token mix 整体迁移就能成立。
疑点三:6 月恰好是海外暑假的开端 + 年中预算执行节奏。欧美企业 IT 采购周期里,6 月通常是年中结算与预算重置窗口,欧洲与拉美的 enterprise token 用量也会因夏季假期出现 10–15% 的结构性回落。把 6 月单月读数当成趋势,等于把季节性扰动当成了结构变化——这是指数信号层面最大的风险,也是这一节标题把「暑假」写出来的原因。
把这三个疑点叠起来,6 月拐点既可能是「routing 已经跨过企业 CFO 门槛」的结构性拐点,也可能是「6 月这一期加权样本出现了 cache 命中率 + 暑期 + 预算周期三力共振」的一次性扰动——7–9 月需要至少三个独立来源的数据点连续印证才能定论。这也是为什么后面「接下来看什么」把 Artificial Analysis / Helicone / OpenRouter 的 7 月读数放到第一位——指数本身需要被第三方交叉验证,这是这条数据被市场接受之前的最大门槛。
三、剪刀差撑起执行端:低价模型吃 70–80% execution 的 evidence 链
抛开指数读数本身的疑点,真正能撑起「execution token 被低价模型吃掉」这一论断的,是各家官方定价页之间已经结构性拉开的「剪刀差」。下面这张表把 2026 年 7 月仍在售的三家代表档位放在一起:
| 模型 | 档位定位 | 输入 $/MTok | 输出 $/MTok | 与 Opus 4.8 输出价比 |
|---|---|---|---|---|
| Claude Opus 4.8 | frontier 闭源 | $5 | $25 | 1× |
| Claude Fable 5 | frontier 顶端 | $10 | $50 | 2×(更贵) |
| Claude Sonnet 5(优惠期) | 中端 | $2 | $10 | 0.4× |
| Claude Haiku 4.5 | Anthropic 低价 | $1 | $5 | 0.2× |
| OpenAI gpt-5.5 | frontier | $5 | $30 | 1.2× |
| OpenAI gpt-5.5-pro | pro 档 | $30 | $180 | 7.2× |
| OpenAI gpt-5.4 | 中端 | $2.50 | $15 | 0.6× |
| OpenAI gpt-5.4-mini | 低价 | $0.75 | $4.50 | 0.18× |
| OpenAI gpt-5.4-nano | 极低价 | $0.20 | $1.25 | 0.05× |
| DeepSeek-V4-Flash(cache miss) | 开源/低价 | $0.14 | $0.28 | 0.011× |
| DeepSeek-V4-Flash(cache hit) | 缓存场景 | $0.0028 | — | cache 输入便宜约 1785× |
| DeepSeek-V4-Pro | 开源/中端 | $0.435 | $0.87 | 0.035× |
来源:Anthropic 官方定价页、OpenAI 开发者定价页、DeepSeek API 定价页(2026 年 7 月现行)。
把这张表最极端的两列放到一起看:DeepSeek-V4-Flash 的 cache hit 输入 $0.0028/百万 tokens vs Claude Opus 4.8 输入 $5/百万 tokens,相差 1785 倍;即使不算 cache 优惠,DeepSeek-V4-Flash 输出 $0.28 vs Opus 4.8 输出 $25,也有 89 倍 差距。OpenAI 同一家厂商内部 gpt-5.5 输出 $30 与 gpt-5.4-nano 输出 $1.25 之间的价差就有 24 倍,叠加 Batch 50% 折扣、Flex 同价、Priority 2.5× modifier,企业支付价的可调范围进一步放大。
这种「同档内部价差」是 routing 能跑通的设计前提——只有当低价档与 frontier 档之间的差距足够大,prompt cache + model routing 才值得作为预算优化项目投入工程资源。@AlphaguyTrading 给出的「planning 20–30% 走 Claude / GPT、execution 70–80% 走低价模型」工作流模式,放在这张表里就有一个数字化的物理解释——不是「模型真的不行了」,而是「当 1785 倍的 cache hit 价差摆在眼前时,routing 是 CFO 不签字也要签字的工程决策」。
把 20/80 模式套到 token 量上做粗算:假设一家典型企业的 token 量是 100 B tokens/月,过去全 frontier 走 Opus 4.8 档(输入 $5、输出 $25,假设 1:3 输入输出比,加权输出约 $20/百万 tokens),月支出约 $2.0M。如果同样的 workload 改成 25% planning 走 Opus 4.8、75% execution 走 DeepSeek-V4-Flash(cache hit 60% 命中率),加权输出价会跌到 ~$6.5/百万 tokens,月支出降到约 $0.65M——降幅 67%。这就是指数读到的 $1.6–1.7/百万 tokens 大致落在的位置:它不是 frontier 单价下跌,而是整个行业的 token 加权单价被 routing 拖下来。
Planning 与 execution 的边界并不干净
需要诚实指出的一点是,「planning 20–30% / execution 70–80%」的拆法在实操中并不干净。真正的企业 workflow 大致可以分四类,每一类对应不同的价格敏感度和模型需求:
- Hard reasoning / 多步规划(占比约 10–15%):复杂数学、多约束优化、跨系统架构设计、监管合规审查——这一类只能用 frontier,且对 latency 不敏感,客单价最高。
- Coding / Agentic workflow(占比约 25–35%):SWE-bench 风格的代码生成与多文件重构、agent 多步工具调用——主力档是 Sonnet / gpt-5.4 这一档,Opus / gpt-5.5 用在最难 10% 的子任务上。
- Text / 文案 / 客服 / RAG(占比约 40–50%):营销文案、客服回复、文档抽取、内部知识库问答——主力档是 Haiku / gpt-5.4-mini / DeepSeek-V4-Flash,frontier 仅在少数高敏感客户对话中使用。
- Embedding / 分类 / 抽取(占比约 10–15%):结构化抽取、聚类、情感分析、批量标注——主力是专用小模型或 nano 档,纯低价。
如果按这个四类拆分做加权,典型的「双层 routing」模型大致是 5–10% Opus / gpt-5.5、25–30% Sonnet / gpt-5.4、50–60% 低价档、5–10% nano / embedding。这个结构与 @AlphaguyTrading 给出的 20/80 大致对得上,但更细致的拆法显示真正「必须在 frontier 上跑的 workload」可能只有 5–10%,而不是 20–30%——这个数字差异在 ARR 测算上影响巨大。如果 frontier 实际只占 5%,那 Anthropic 收入暴露面比市场预期的还要小一截,这是单一 KOL 指数之外最值得被企业 CFO 追问的一条线。
四、frontier pricing 实际承压:能力溢价正被双向挤压
把视线从指数转向 frontier 模型自身的定价逻辑,会发现一个更结构性的事实:Opus 4.8 比 Sonnet 4.6 贵 67%,比 Haiku 4.5 贵 5 倍,但过去 6 个月里能力差距的扩大速度并没有跟上价格差距。大量 coding agent / RAG / 客服场景在 Sonnet 4.6 上已经够用,只有少量 hard reasoning 场景真的需要 Opus 4.8——这意味着 frontier 单价的「能力溢价」正在被两条力同时挤压:
- 第一条力是「代际差缩小」。Anthropic 在 Sonnet 5 / Opus 4.x 这一档与上一代 Sonnet 4.6 / Opus 4.7 相比,能力提升主要来自 reasoning / tool-use / context window 的细节优化,而不是「能做 / 不能做」这种根本性突破——市场愿意为细节差异付的 premium,远低于为代际跃迁付的 premium。
- 第二条力是「低价档能力上行」。gpt-5.4-mini、DeepSeek-V4-Flash、Claude Haiku 4.5 在过去两个季度已经从「勉强能用」上升到「production ready」,RAG / 客服 / 抽取场景的边际能力差距被压到企业能接受的范围——当 50% 的 workload 都能在 $1/百万 tokens 以下跑通时,frontier 的 $25/百万 tokens 卖的就是剩下 5–10% 的能力,而不是覆盖全部 workload 的入场券。
如果 Sonnet 5 的 8 月 31 日优惠期结束后回到 $3/$15 标准价,它与 gpt-5.4($2.50/$15)和 DeepSeek-V4-Pro($0.435/$0.87)之间的价格优势会同时被压缩——Sonnet 5 标准价比 gpt-5.4 输入贵 20%、输出同价;比 DeepSeek-V4-Pro 输入贵 6.9 倍、输出贵 17 倍。这是 Anthropic 在 frontier 之外唯一还有价格吸引力的一档,优惠期一过,如果大客户不接受提价而是迁移,Anthropic 9 月起大概率会在 Opus 4.8 之上再开一档更激进的 promo 来补位——这条 promo 能不能跑出来,本身就是「能力溢价是否仍在」的市场化测试。
早报观点
判断一:6 月这条数据最该被记住的地方,是它第一次把 routing 这个技术话题推到了企业 CFO 能读懂的位置。
过去 18 个月,「模型路由」是 infra 工程师在 Notion 内部文档里写的事;DeepSeek-V4-Flash cache hit 输入 $0.0028/百万 tokens 与 Claude Opus 4.8 输出 $25/百万 tokens 之间的 1785 倍剪刀差,过去只有 FinOps 团队会去算。@AlphaguyTrading 这次做的事,本质上是用一个加权指数把这件事压缩成了一条单月可读的曲线——指数本身的精度不够(加权口径未公开、加权样本未披露、cache hit 处理方式不明),但它把这件事从「技术圈话题」推到了「CFO 能引用」的门槛。即便 7–9 月这条曲线被第三方平台反驳、修正甚至推翻,「routing 已经被市场作为一个独立叙事看待」这件事本身不会回退——后续 1–2 个季度会出现更多企业级公开 case study(尤其是客服、coding、文案、内部 RAG 这四类典型 execution 场景),这次只是先把信号放出来。
判断二:6 月这个拐点还不能直接视作趋势开端。它更像「暑假 + 预算周期 + cache 命中率」三力共振的一次性扰动,需要 7–9 月至少三个独立数据点连续印证。
加权口径未公开是这条数据被放上头条但不打算把它的拐点读数当成定论的根本原因。具体地说,6 月的 15% 单月跌幅完全在 cache 命中率结构性变化 + 海外暑假企业 IT 用量回落 + 年中预算重置窗口这三股力的可解释范围内,不需要假设 frontier token 收入被低价档系统性挤压就能成立。真正的验证节点是 7–9 月三连:Artificial Analysis / Helicone / OpenRouter 是否在 7–8 月公开 token 加权均价;DeepSeek 7 月 24 日命名统一后的 API 日均调用量与 cache hit 占比;Qwen / GLM 是否在 Q3 公布 routing 数据或企业 case study。如果这三股独立来源的数据都指向「加权均价继续在 $1.6 附近甚至向下」,拐点就坐实了;只要有一项显著偏离,这条指数的 6 月读数就只是「那个夏天的故事」——这也意味着看 frontier pricing 实际承压的真正时间窗口不是 6 月,也不是 7 月,而是 9 月 Anthropic 的 ARR 披露 + Sonnet 5 标准价生效后的客户行为叠加在一起的复合读数。
判断三:frontier pricing 的确在承压,传导链条应读作「能力溢价被代际差缩小 + 低价档上行双向挤压 → frontier 收入暴露面比预期小一截」。
@AlphaguyTrading 提到「半导体和存储会被间接影响」这条传导链,成立的前提是 frontier token 量继续线性上行。但 frontier token 量继续上行的前提是 frontier pricing 还能稳住——而 frontier pricing 正在被 Opus 4.8 vs Sonnet 4.6 的 67% 价差 vs 6 个月里能力差距扩大不足 + gpt-5.4-mini / DeepSeek-V4-Flash / Claude Haiku 4.5 在 RAG / 客服 / 抽取场景已经达到 production ready 这两条力同时挤压。Anthropic ARR 风险不是空穴来风,但传导路径不是「token 单价 → 半导体订单」——半导体 / 存储的实际订单周期是 12–18 个月,token 单价拐点对供应链的传导至少滞后两个季度,@AlphaguyTrading 提到的「半导体和存储的次级传染」是把估值层面的拥挤交易回撤风险混进来了,不应混为一谈。真正需要盯的是 Anthropic 自己 7–9 月的 ARR / run-rate + enterprise 续费率,以及 Sonnet 5 在 8 月 31 日优惠期结束后的客户行为——大客户接受提价、迁移到 Sonnet 4.6 / 4.5、还是开始与销售谈 deep discount,这是「能力溢价是否仍在」的最直接读数,也是判断这条指数未来走势的关键风向标。
接下来看什么:先验证指数本身,再谈趋势
指数本身还需要第三方独立验证,以下 4 个可验证跟踪点优先级递减,前两个直接对指数口径做交叉印证,后两个看 frontier pricing 是否真的承压:
-
Artificial Analysis / Helicone / OpenRouter 在 7–8 月是否公开 token 加权均价:这是最直接的反方检验——也是这条数据被市场接受之前的最大门槛。如果他们公开的指数与 $1.6–1.7/百万 tokens 一致,拐点就被坐实;如果显著偏离,指数的口径偏差就要重新评估,6 月这个拐点可能就只是「那个夏天的一次性扰动」,而非趋势的开端。
-
DeepSeek 7 月 24 日命名统一后的 API 日均调用量与 cache hit 占比:这是 70/20 工作流假设是否成立的最直接读数。V4-Flash / V4-Pro 命名统一后,如果 API 日均调用量继续上行、cache hit 占比稳定在 40% 以上,说明 execution 端被低价档吃掉的趋势是结构性的;如果调用量持平、cache hit 占比反而下降,则说明 routing 假设被高估,frontier 收入暴露面比想象中小没那么夸张。
-
Anthropic 7–9 月 ARR / run-rate 与 enterprise 续费率:重点看 Mythos 5 / Fable 5 / Sonnet 5 后续版本是否把 frontier 与低价档的能力差距重新拉开。如果 ARR 显著低于市场线性外推,frontier pricing 实际承压这条判断就被坐实;如果 ARR 与市场预期一致,说明 Sonnet 5 优惠期结束 + 标准价回到 $3/$15 暂时没有动摇大客户基础。
-
Claude Sonnet 5 在 9 月 1 日回到 $3/$15 标准价后的客户行为:大客户是接受提价、迁移到 Sonnet 4.6 / 4.5、还是开始与销售谈 deep discount——这一个数据点能直接反映「能力溢价」是否仍在。如果 9–10 月出现显著比例的大客户迁移,frontier pricing 实际承压的传导链就完整跑通了。
指数原始曲线与 6 月拐点(推文附图)
@AlphaguyTrading 在推文里附了一张指数曲线图,呈现 2025 年 12 月到 2026 年 6 月的指数走势:从年初的约 $1/MTok 平稳上行、5 月底冲高到接近 $2/MTok,6 月单月明显回落到 $1.6–1.7/MTok 区间。该图未标注加权口径、未标注样本范围,目前是单一来源,适合作为方向性读数而非精确基准。原始图:https://pbs.twimg.com/media/HMXuWrPbMAAopKE.png
{kind=link}